
Modern Architecture, RVA23-Aligned
- Fully compliant with the RVA23 RISC-V specification
- Comparable PPA to Arm Neoverse V3 / Cortex-X4
- Standard AMBA CHI.E coherent interface for SoC and chiplet integration
- Co-architected with Veyron E2 for seamless vector, AI acceleration, and big-little style heterogeneous compute configurations
Extreme Performance and Power Efficiency
- Optimized for high IPC and 3+ GHz core frequency
- 15-wide out-of-order core: fetch, decode, and execute up to 15 instructions per cycle
- Balanced performance-per-watt architecture optimized to scale from hyperscale to edge environments
- Advanced power gating and DVFS support for fine-grained control
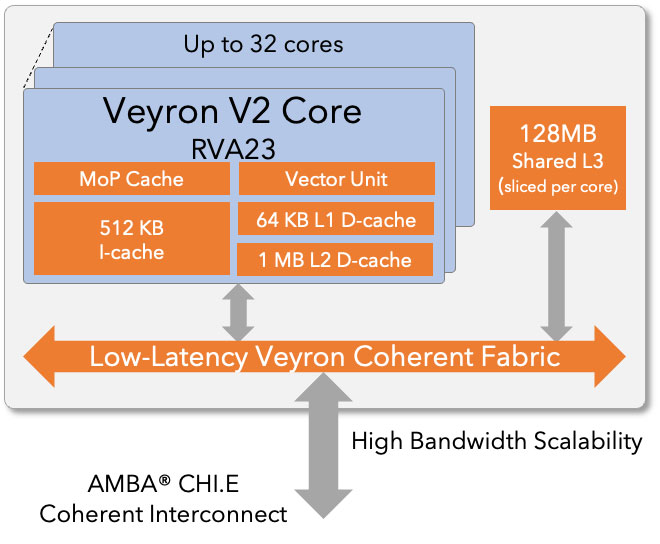
- Up to 32 cores per cluster with decoupled front-end and advanced branch prediction
- High-performance 512-bit RVV 1.0 vector unit with INT8 and BF16 support
- Integrated matrix unit delivering up to 0.5 TOPS/GHz/core (INT8)
- Macro-op caching and aggressive prefetching for instruction and data streams
Advanced Cache & Cluster Architecture
- 1.5 MB private L2 cache per core
- Shared L3 cache configurable from 1–4 MB per core (up to 128 MB per cluster)
- Low-latency coherent cluster fabric
- High-bandwidth shared resources optimized for multithreaded workloads
Server-Class Reliability, Virtualization, and Optimization
- Full architectural virtualization support for cloud-native workloads
- Comprehensive RAS:
- ECC on all caches and functional RAMs
- End-to-end data poisoning protection
- Background error scrubbing and logging
- Built-in side-channel attack mitigation
- Comprehensive performance profiling and tuning support
Flexible IP Integration for Custom SoCs
- Clean, portable RTL – no custom macros or proprietary RAMs
- Modular multi-core cluster design for high-core-count scaling
- Integration-ready with standardized IP interface

Chiplet Integration & Packaging
- Standardized chiplet interfaces:
- Ventana D2D multi-protocol controller
- UCIe PHY for chiplet-based system integration
- Compatible with cost-effective organic packaging for volume deployment
- Configurable TDP for deployment across power-performance targets
- Turbo profile management with real-time power behavior control
- Digital power models at both core and cluster level for dynamic scaling